Optimizations: Methodology
Applying Ranges and Steps
- It is ALWAYS better to apply ranges to the free parameters (especially
for the simulated Annealing). This prevents the geometry from taking
unreasonable configurations if the free parameters take too high a value.
- Too big a step makes it useless, but too small a step can prevent fast
convergence to a solution. If you are not sure, do not attribute any step but
assign ranges.
- Steps are only indicative starting values used by the algorithms: To
converge toward optimal values both Gradient and SA algorithms need to reduce
the steps between consecutive trials. If the search makes progress in the
same direction (local optimum not detected), the step increases to speed up
the localization of the local (and global) optimum. As soon as an optimum is
located, Gradient and SA do not behave the same way: The gradient algorithm
reduces its step to reach convergence inside this optimum. The SA makes the
step evolve depending on the history of the run according to a complex law.
It must be noticed that in no case, the step remains constant.

Creating and Using Parameters as Free Parameters
When working in an optimization, since you cannot create external
references, you can select:
- The parameters located above the optimization: The immediate Part,
Product, Product of Part, Analysis Manager.
- The parameters located below each son of the local literal father. Only
if those parameters are loaded.
Note that:
- if you select a node in the tree, the parameters published by the
selected node will be displayed only if they belong to the parameters
mentioned above.
|
- even if the optimization is at an upper level, the selection of a
parameter is conditioned by the fact that the parts must be in design
mode if you want to select parameters located below a Part.
|
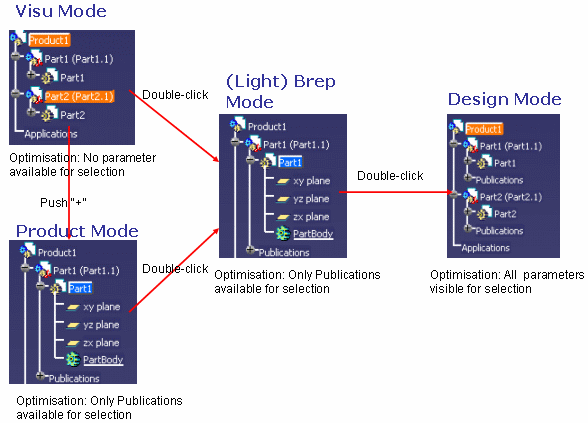
Depending on the loading mode in CATIA, parameters can be selected or not
(see graphic below).
Algorithms and Objective Function
- In general, the shape of the Objective function is unknown. It is
therefore better to begin with a Simulated Annealing and to refine the
results with a gradient descent. This approach is slow but works for a larger
amount of functions.
- If the properties of the curve are known (continuous, differentiable at
all point and with a single optimum), then the gradient can be used straight
on. It is usually faster than the Simulated Annealing algorithm.
- If you have to restart the optimization because you are not satisfied
with the first result, reduce the ranges on the free parameters and/or reduce
the steps.
Algorithms Use
- Approximating a solution with the Simulated Annealing can be quickened by
reducing the consecutive bad evaluation stopping criterion to 15 or 20.
However, this will increase the risk of a premature convergence to local
optimization especially if the optimized problem contains several free
parameters.
- For both algorithms, the final results provided can be refined by
removing one or several variables and by restarting the optimization.